首页 > 机器学习 > 正文
原创文章,转载请注明出处!
本文链接:https://leo4678.github.io/posts/ml-normalization-standardization.html
归一化和标准化
标签:特征工程
2019-02-18
目录
首先需要明确一点,归一化和标准化处理的是连续型变量,离线型变量需要使用其他方法来做处理(编号,one-hot,mutl-hot,embedding等)
1. 归一化Normalization
1.1 归一化定义
归一化是将原始空间不同维度的数据转换成同一量纲,常用方法有两个:
- Rescaling
- Mean normalization
其中,min(x)是样本中特征最小值,max(x)是样本中最大值,mean(x)是样本均值
它的目的是是使各个特征维度对目标函数的影响权重是一致的
1.2 归一化优点
-
提高迭代求解的收敛速度(一般情况下bias项初始化时是一个较小的值,因变量一般是规模较小的值,自变量过大或者过小,就需要过小或者过大的bias来拟合)
-
提高迭代求解的精度(较大或较小的因变量在数据运算时,更容易产生较大或较小的数据,而计算机在表达较大或者较小的数据时会损失一定的精度,往往采用缩小或放大原始变量的方式来提高其精度)
1.3 归一化缺点
- 归一化会改变原始样本分布(归一化之后,样本之间的距离会发生变化)
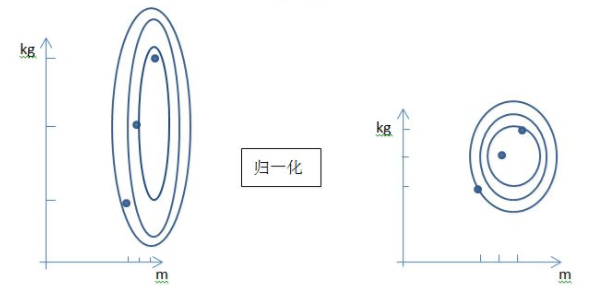
上图中y轴表示体重,x轴表示身高,此二维平面表达了由体重和身高构建的样本集。左侧图表示原始分布,可以看到体重和身高的量纲差距很大。右图为对特征做归一化之后的分布,明显可以看到其分布已经发生变化(形状不发生变化,样本之间的距离不发生变化,可以认为分布不发生变化)
- 归一化使用的最大值和最小值容易受到异常点影响,鲁棒性差,只适合传统精确小数据场景
2. 标准化Standardization
2.1 标准化定义
常用的标准化公式:
- z-score
其中\(\bar{x}\)是均值,\(\sigma\)是标准差
标准化对原始数据做伸缩变换的目的是使得不同度量之间的特征具有可比性,同时不改变原始数据的分布
2.2 标准化优点
- 使得不同维度的特征具有可比性,对目标函数的影响体现在几何分布上,而非数值上
- 不改变原始数据的分布
- 鲁棒性好
2.3 标准化缺点
- 只能对原始数据进行缩放,不能将其映射到某一区间范围内,相比归一化,收敛速度会变慢
3. 归一化和标准化的区别
- 归一化是一个绝对值,其目的是消除量纲对最终结果的影响,隐性假设了不同维度特征对目标的影响权重是一样的,如:两个人体重相差10KG,身高相差0.02M,在衡量两个人的差别时体重会把身高的差别完全掩盖,归一化之后不会有这样的问题
- 标准化是一个相对值,它表达的是原始值和均值之间差多少个标准差,也有去除量纲的功效,同时还带来两个附加好处:均值为0,标准差为1
- 均值为0的好处:均值为0表名数据以0为中心左右分布,而在机器学习领域很多函数都是以0为中心左右分布的,这样会是的模型更容易拟合数据,如:去中心化的数据做SVD等价于在原始数据上做PCA,Sigmod/Tanh/Softmax激活函数等
- 标准差为1的好处:使用欧氏距离计算特征重要程度时,得到每个特征的重要程度正比于其在该数据集上的方差。标准差为1,则说明每个特征的重要程度是一样的
4. 如何选择
- 要不要做归一化/标准化:SVM(数据伸缩后,最优解和原来不等价,除非原始数据各维分布范围比较接近,否则必须归一化/标准化处理,以免模型参数被分布范围较大或者较小的数据支配),线性模型(数据伸缩后,最优解和原来等价,但是实际使用迭代法求解时,有可能收敛很慢甚至不收敛,所以最好也进行归一化/标准化处理),树模型(不需要)
参考:在进行数据分析的时候,什么情况下需要对数据进行标准化处理?,为什么归一化/标准化之后,会收敛更好?
- 归一化和标准化如何选择:
- 确认每个维度特征对目标函数影响一致,使用归一化更好(归一化更麻烦)
- 想保留原始分布,且需要更加适合噪音,则选择标准化更好(标准化更简单)
- 以实验结果为准
原创文章,转载请注明出处!
本文链接:https://leo4678.github.io/posts/ml-normalization-standardization.html
上篇:
逻辑/线性回归/GLM
下篇:
C++ gdb调试