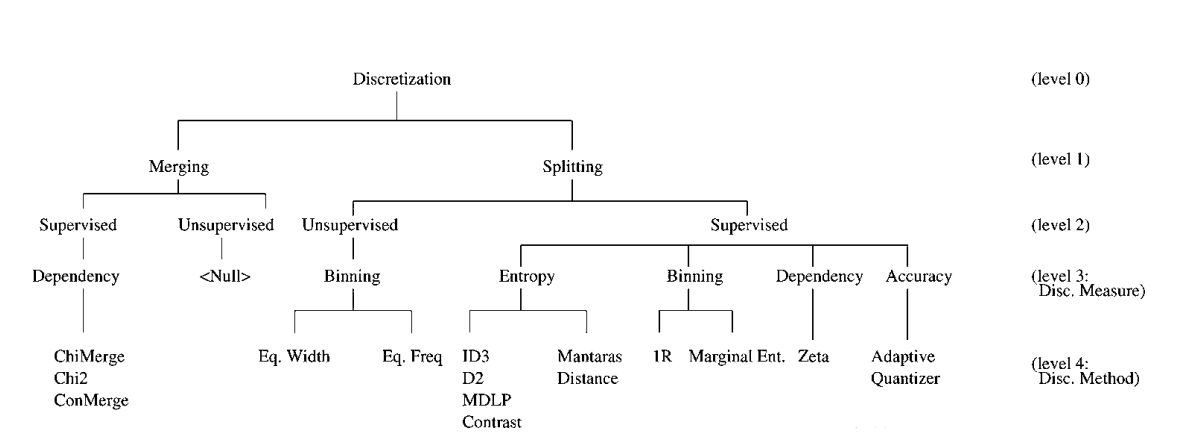
离散化
标签:特征工程目录
1. 离散化是什么
数据可以分为离散数据、连续数据、nominal数据(无序数据)。离散化(Discretization)指的是将连续型变量分布变为离散型变量分布
2. 为什么要做离散化
参考 知乎问题连续特征的离散化:在什么情况下将连续的特征离散化之后可以获得更好的效果?严林的回答
- 计算简单
大范围运算变为向量运算,如:原始特征为age=28进行的运算,变为按照age<=10, 10<age<=20, 20<age<=30, 30<age<=40, 40<age<=50,age>50划分的[0, 0, 1, 0, 0, 0]进行的向量运算
- 增强泛化能力
抗噪:异常值总归会映射到一个离散区间上,这样会对模型造成较少的影响,比如:一个特征是age>30是1,否则0。 如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰
抗过拟合:首先明确一下过拟合产生原因,有噪声、训练数据不足、训练模型过度导致模型非常复杂,参考大白话解释模型产生过拟合的原因。既然离散化有抗噪的作用,那么就有一定程度的抗过拟合
稳定:由于离散化描述的是一段连续型值,那么在该连续型值范围内,它们对模型的影响是一致的,比如:如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问
- 增强模型表达能力
逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合。 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力
- 引入人类先验经验
人类根据日常事实进行的总结,来源于大量观察的数据,这种先验知识有可能对模型有很强的帮助。比如:判断一个学生是否是好学生,一个可以参考的维度是成绩,成绩通常是一个[0, 100]之间的浮点数,如果想让模型知道85比75好,75比59好,可能需要较多的样本量。但是老师知道85比75好,75比59好,通常会分成优秀、合格、不合格等,这样需要较少的样本量,模型就知道评级优秀的成绩更好,是好学生的可能性更大
离散化总结:李沐曾经说过,模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。就看是喜欢折腾特征还是折腾模型了。通常来说,前者容易,而且可以n个人一起并行做,有成功经验;后者目前看很赞,能走多远还须拭目以待
3. 离散化常用方法
如何衡量离散化好坏?
如果离散化区间内部class label比较一致,而且不同离散化区间之间class分布有较大的差异,这种离散化结果应该是比较好的
3.1 Merging
- ChiMerge
卡方检验:通过理论值与实际观测值之间的差异来判断不相关(自变量和因变量没有相关性,相互独立)假设是否成立。计算出卡方值后,通过查临界值表得到独立假设成不成立的可能性大小。卡方检验有很多应用,例如特征选择、异常值检测等。这里我们主要讨论卡方检验怎样用在特征离散化的过程。参考统计学-卡方检验和卡方分布
假设:X的相邻两个区间与Y(Label)不相关(独立),不太可能出现Y的分布在X两个区间中的某一个过于聚集,分布应该平均,卡方值越小,则假设越不成立,两区间不应该独立,应该合并
卡方(Chi)值计算方式如下图:

m表示自变量的可能取值,这里表示X的两个区间;k表示Y的label取值情况;\(A_{ij}\)表示区间i,label为j的样本个数;\(E_{ij}\)表示区间i,label为j的期望数;
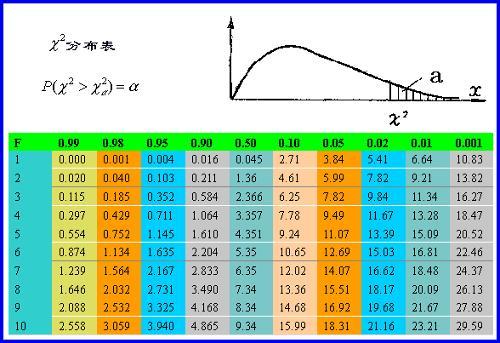
1.按照自变量排序,根据卡方值表确定阈值t。下图表中,纵轴表示自由度,横轴表示概率置信度。自由度=(X区间个数-1)*(Y中label类别数-1)。 如:(0.05, 1)=>3.84表示假设成立有95%的可能性,自由度为1的卡方临界值为3.84,计算得到的卡方值<3.84则假设不成立,区间应该合并
2.计算每个相邻区间的卡方值
3.合并<t的区间
4.判断是否终止,否则重复步骤2
- 聚类方法
基于其他相关数据来计算样本间距离,距离近则进行合并
3.2 Spliting
3.2.1 Unsupervised
- Width/等距
等宽法即是将属性值分为具有相同宽度的区间,区间的个数k根据实际情况来决定。比如属性值在[0,100]之间,最小值为0,最大值为100,我们要将其分为4等分,则区间被划分为[0,25] 、[26,50] 、[51,75]、[75,100],每个属性值对应属于它的那个区间
- Freq/等频
区间划分按照个数k来决定。 比如有100个样本,我们要将其分为k=4部分,则每部分的长度为25个样本
3.2.2 Supervised
- 1R离散化
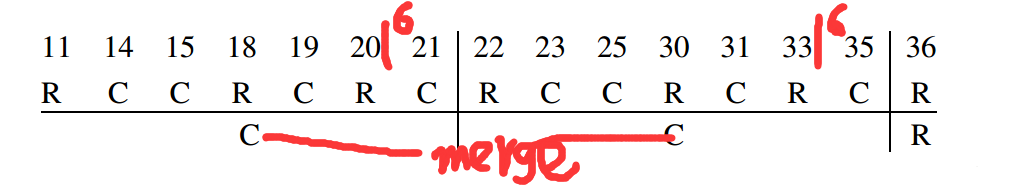
如上图11,14,… 36为自变量(X), R, C,… R为因变量(Label)
1.按照变量大小关系进行排序,如上图的11, 14, 15等
2.划分区间,如上图红色部分每个区间最少6个实例,那么11-20分为一个区间,21-33分为一个区间,35-36分为一个区间
3.区间边界合并,如上图11-20的边界21类别为C与11-20的类别C一致,则进行合并,同理35也进行合并
- 信息增益Split(D2)
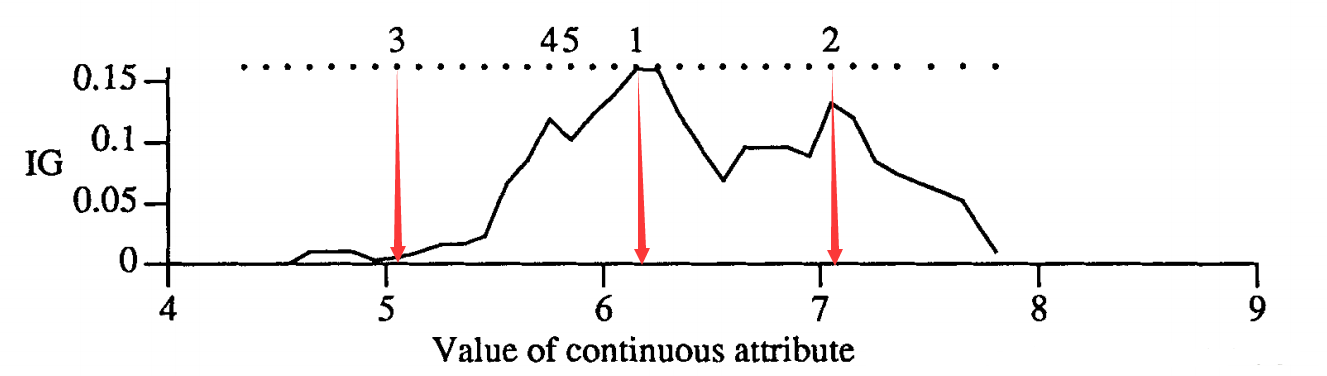
图上的点表示候选分裂点,数字1-5表示选中的五个分裂点,其中点1是用ID3方法选中的第一个分裂点,图中的IG曲线表示特征未离散化之前的信息增益。从图中可以看到,点1把数据分为左右两个部分,接下来分别计算左右两边的信息增益。对左边而言,点3作为分裂点较好,虽然点3在分裂之前的信息增益IG很小,但仅仅考虑左边点3是比较好的分裂点。其余的分裂点的选取也都一样。 D2算法什么时候停止呢?D2停止条件可以视情况而定,这里简单列举下几个可选的终止条件: 区间里的数据很少;区间里的数据属于同一类;每个候选分裂点的IG都差不多等
原创文章,转载请注明出处!
本文链接:https://leo4678.github.io/posts/ml-feature-engineering-discretization.html