损失函数
标签:损失函数目录
参考https://blog.csdn.net/u010976453/article/details/78488279
1. 损失函数定义
损失函数被用来衡量两个分布之间的差异程度,是一个非负实值函数,通常用\(L(Y,f(x))\) 来表示。损失函数越小,模型就越准确。损失函数是结构风险函数的核心部分。模型的风险结构包括两部分,一部分来自经验风险(即“拟合样本分布的差距”),一部分来自结构风险(“模型本身结构带来的过拟合风险”,即正则项),其数学表达如下:
2. 常用损失函数
损失函数必须是一个对称函数(PS:大家可能会说用屁股想都知道,但是我自己确实是看了几幅\((y-f(x), Loss)\)函数图才感触到,突然意识到不自己从根源思考是多么可怕)
2.1 回归模型常用损失函数
参考机器学习常用5个回归损失函数,注以下公式中\(f(x)\)为预测值,\(y\)为标签
2.1.1 MSE/均方误差/L2损失
其中\(y_{i}\)表示样本i的实际label,\(y_{i}^{p}\)表示样本i的预测值
# true: Array of true target variable
# pred: Array of predictions
def mse(true, pred):
return np.sum((true - pred)**2)
# also available in sklearn
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
2.1.2 MAE/平均绝对值误差/L1损失
其中\(y_{i}\)表示样本i的实际label,\(y_{i}^{p}\)表示样本i的预测值
# true: Array of true target variable
# pred: Array of predictions
def mae(true, pred):
return np.sum(np.abs(true - pred))
# also available in sklearn
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
2.1.3 Huber损失/平滑的平均绝对误差
MSE和MAE兼有的问题是:在某些情况下,上述两种损失函数都不能满足需求。例如,若数据中90%的样本对应的目标值为150,剩下10%在0到30之间。那么使用MAE作为损失函数的模型可能会忽视10%的异常点,而对所有样本的预测值都为150。这是因为模型会按中位数来预测。而使用MSE的模型则会给出很多介于0到30的预测值,因为模型会向异常点偏移。上述两种结果在许多商业场景中都是不可取的。对于这种应用场景,常用处理办法有两种,一是调整目标变量,另一种是调整损失函数,由此引出Huber损失。
# true: Array of true target variable
# pred: Array of predictions
def huber(true, pred, delta):
loss = np.where(np.abs(true-pred) < delta , 0.5*((true-pred)**2), delta*np.abs(true - pred) - 0.5*(delta**2))
return np.sum(loss)
2.1.4 Log-Cosh损失
优点:对于较小的x,log(cosh(x))近似等于x^2/2,对于较大的x,近似等于abs(x)-log(2)。这意味着logcosh基本类似于均方误差,但不易受到异常点的影响。它具有Huber损失所有的优点,但不同于Huber损失的是,Log-cosh二阶处处可微。但Log-cosh损失也并非完美,其仍存在某些问题。比如误差很大的话,一阶梯度和Hessian会变成定值,这就导致XGBoost出现缺少分裂点的情况。
# true: Array of true target variable
# pred: Array of predictions
def logcosh(true, pred):
loss = np.log(np.cosh(pred - true))
return np.sum(loss)
2.1.5 问题
问题1:回归问题,大家大多使用MSE和MAE,对于这两者有什么区别,如何选择?
MSE优点:计算简单(只有一次平方操作),函数可导(平滑凸函数,有一个全局最优点)
MSE缺点:由于取了平方,当绝对值误差大于1时,会进一步增大误差,特别不适合处理异常点(这里指label分布非常不平衡),鲁棒性差
MAE优点:能够容忍异常点,不至于让模型有偏,鲁棒性好
MAE缺点:计算复杂(存在绝对值操作),函数存在不可导点,另不论绝对值误差大小,更新梯度始终相同(MSE则不存在该缺点)
总结:处理异常点时,MAE损失函数更稳定,但它的导数不连续,因此求解效率较低。MSE损失函数对异常点更敏感,但通过令其导数为0,可以得到更稳定的封闭解。
问题2:Huber损失相比MAE和MSE的优点是什么?它有什么缺点呢?
MAE最大问题是梯度不变,Huber损失能够解决这个问题。MSE鲁棒性差,Huber损失能够在异常点时,调整其损失值,防止模型过偏。
Huber损失的缺点是,它包含一个超参数,需要不断调整\(\delta\)。
问题3:Log-Cosh损失提到其在二阶处处可微,那么为什么需要二阶导数呢?
许多机器学习模型如XGBoost,就是采用牛顿法来寻找最优点。而牛顿法就需要求解二阶导数(Hessian)。因此对于诸如XGBoost这类机器学习框架,损失函数的二阶可微是很有必要的。

问题4:Log-Cosh损失为什么不常用?
误差很大的话,一阶梯度和Hessian会变成定值,这就导致XGBoost出现缺少分裂点的情况。
2.2 分类模型常用损失函数
回归问题常用\(y-f(x)\)作为残差,分类问题类似残差概念被称为margin,常用\(yf(x)\)来计算。
2.2.1 zero-one loss/0-1损失
上述公式,假定任务类型为二分类,label为-1或者+1,f(x)>=0 分类为+1,f(x)<0 分类为-1。 0-1损失对每个错分类点都施以相同的惩罚,这样那些“错的离谱“ (即 \(margin \rightarrow -\infty )\)的点并不会收到大的关注,这在直觉上不是很合适。 另外0-1损失不连续、非凸,优化困难,因而常使用其他的代理损失函数进行优化。
2.2.2 Hinge Loss/铰链损失/合页损失
Hinge loss为SVM中常用的损失函数,标签要求 y为-1或者+1,使得SVM仅通过少量的支持向量就能确定最终超平面。
当\(y=+1\)时
当\(y=-1\)时
总之,如果被正确分类,损失是0,否则损失就是\(1-f(x)\)。下图的红色虚线就是hinge loss
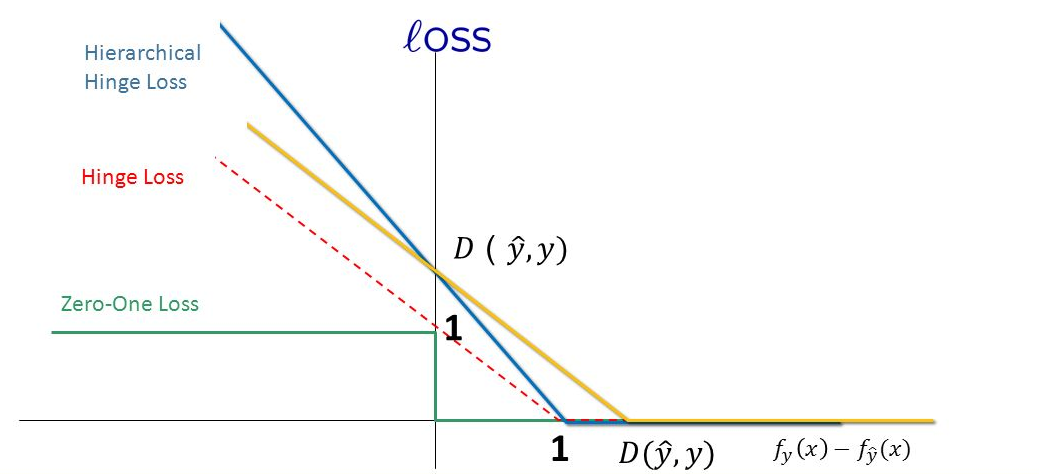
Hinge 可以用来解间距最大化的问题,最有代表性的就是SVM问题:
\[
\underset{w,\zeta}{argmin} \frac{1}{2}||w||^2+ C\sum_i \zeta_i \\
st.\quad \forall y_iw^Tx_i \geq 1- \zeta_i \\
\zeta_i \geq 0
\]
将约束项进行变形,则为:
\[
\zeta_i \geq 1-y_iw^Tx_i
\]
进一步地,可以把损失函数写为:
\[
\begin{equation}\begin{split}J(w)&=\frac{1}{2}||w||^2 + C\sum_i max(0,1-y_iw^Tx_i) \\
&= \frac{1}{2}||w||^2 + C\sum_i max(0,1-f(x_i)) \\
&= \frac{1}{2}||w||^2 + C\sum_i L_{Hinge}(f(x_i))
\end{split}\end{equation}
\]
因此, SVM 的损失函数可以看作是L2-norm和Hinge loss之和。
2.2.3 Logistic Loss/logi损失
标签要求为-1或者+1
在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数,接着取对数求极值等等。而逻辑回归并没有求似然函数的极值,而是把极大化当做是一种思想,进而推导出它的经验风险函数为:最小化负的似然函数\(\max F(y, f(x)) \rightarrow \min -F(y, f(x)))\),从损失函数的视角来看,它就成了Softmax 损失函数了。
log损失函数的标准形式:
\[
L(Y,P(Y|X)) = -\log P(Y|X)
\]
取对数是为了方便计算极大似然估计,因为在MLE中,直接求导比较困难,所以通常都是先取对数再求导找极值点。损失函数\(L(Y, P(Y|X))\)表达的是样本X 在分类Y的情况下,使概率\(P(Y|X)\)达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大)。因为log函数是单调递增的,所以\(logP(Y|X)\),因此在前面加上负号之后,最大化\(P(Y|X)\)就等价于最小化\(L\)了。
2.2.4 Cross Entropy Loss/Softmax Loss/交叉熵损失/互熵损失
标签要求 y = 0 或者 1
在逻辑回归中,当定义\(label\in {-1,+1}\)或者\(label\in {0,1}\),其损失函数是不一样的,推导如下:

2.2.5 Exponential Loss/指数损失
主要用于Adaboost 集成学习算法中
\[
L(Y,f(X)) = \exp [-Yf(X)]
\]
主要应用于 Boosting 算法中,在Adaboost 算法中,经过 m 次迭代后,可以得到
\[
f_m(x)=f_{m-1}(x) + \alpha_m G_m(x)
\]
Adaboost 每次迭代时的目的都是找到最小化下列式子的参数\(\alpha\)和G:
\[
\arg \min_{\alpha,G} = \sum_{i=1}^N \exp[-y_i(f_{m-1}(x_i) + \alpha G(x_i))]
\]
所以,Adabooost 的目标式子就是指数损失,在给定n个样本的情况下,Adaboost 的损失函数为:
\[
L(Y,f(X)) = \frac{1}{2} \sum_{i=1}^n \exp[-y_if(x_I)]
\]
2.2.6 modified Huber loss
标签要求 y = -1 或者 +1
modified huber loss结合了hinge loss和logistic loss的优点,既能在 yf(x) > 1 时产生稀疏解提高训练效率,又能进行概率估计。另外其对于 (yf(x) < -1) 样本的惩罚以线性增加,这意味着受异常点的干扰较少,比较robust。scikit-learn中的SGDClassifier同样实现了modified huber loss。
原创文章,转载请注明出处!
本文链接:https://leo4678.github.io/posts/ml-loss-functions.html