YoutubeDNN 论文中涉及到的十大问题
标签:推荐目录
1. YoutubeDNN主要内容
1.1 召回网络
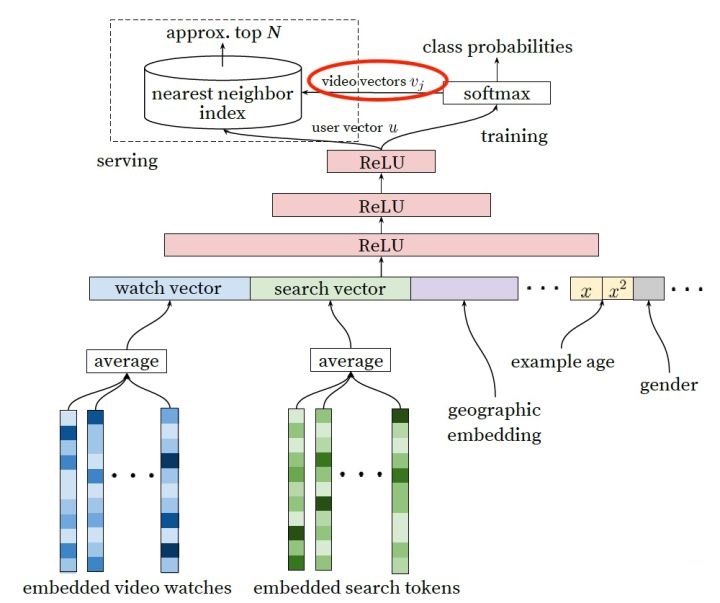
上图网络即为YoutubeDNN中召回阶段使用的网络。可以看到使用特征包括‘用户看过视频embedding’,‘用户搜索tokens embedding’,‘位置embedding’,‘用户画像-年龄/性别’,经过三层网络计算,训练阶段外加一层softmax层,线上使用加一层nearest neighbor index。
1.2 精排网络
上图网络即为YoutubeDNN精排阶段使用网络。和召回层网络的区别主要是特征工程,可以看到精排层使用了更加细粒度、更加丰富的特征。具体一点,从左至右的特征依次是:
-
impression video ID embedding: 当前要计算的video的embedding
-
watched video IDs average embedding: 用户观看过的最后N个视频embedding的average pooling
-
language embedding: 用户语言的embedding和当前视频语言的embedding
-
time since last watch: 自上次观看同channel视频的时间
-
previous impressions: 该视频已经被曝光给该用户的次数
2. YoutubeDNN中十大问题
2.1 文中召回网络将推荐问题转换成多分类问题,有多少个视频就有多少类,因此在百万视频或者更大量的时候,使用softmax训练是很低效的,这个问题youtube是如何解决的?
Youtube应该是借鉴了word2vec的解决思路。有两种办法,一是Negative Sampling,另一种是Hierarchical Softmax。
- Negative Sampling/负采样
顾名思义,就是在做Softmax时,并不使用全量分类,而是在确定正样本之后,选取一定量的负样本,这样可大大减小多分类的数目。 Negative Sampling会为每一个分类构建一组向量参数\(\Theta\),采用了二元逻辑回归来求解模型参数。训练时,首先获取一条正样本,通过负采样,得到了neg个负例\((x, pred_{i})\)i=1,2,..neg。为了统一描述,我们将正例定义为\(pred_{0}\)。
在Negative Sampling有两个问题,一个是如何负采样,一个是模型参数求解
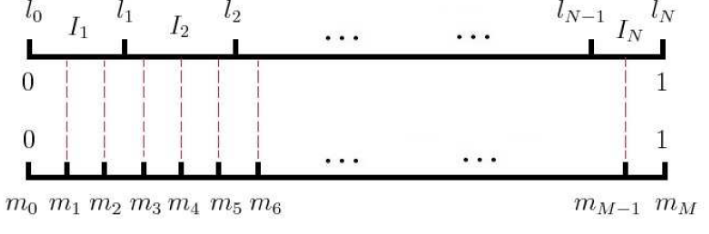
1. 如何负采样
按照样本中不同类别的频率,划分一个长度为1的线段,然后在该线段上采样。具体做法是,先将长度为1的线段划分为M份,M»N(假定有N类),这样可以保证每个类别都有对应的线段,M中的每一个点都会落在某一类上。采样时,只需要从M个点中采出neg个位置就行。
2. 模型参数求解
在逻辑回归中,正例期望满足:
上式表达的含义是,对于输入\(x\),预测为\(pred_i\)这个类别的概率,实际label为正例,由于假定了\(pred_{0}\),所以i为0
负例期望满足:
最大化期望:
跟LR一模一样啦,可以求解模型参数
- Hierarchical Softmax/分层Softmax
参考霍夫曼树的思想,使用一个树结构的决策树来代替Softmax计算,这样能将原始Softmax的N运算降低到log2N。下图表示一个\(w_{2}\)分类的计算过程。
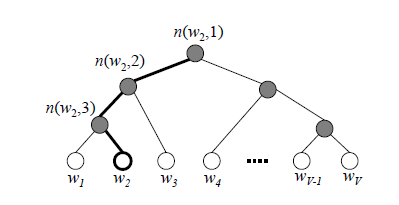
隐层输出的向量从根节点输入,然后进行如下公式的计算,分类为-则走左侧,分类为+则走右侧,直到叶子节点,每一个叶子节点会对应一个类别。
在某一个内部节点,要判断是沿左子树还是右子树的标准就是看\(P(-)\)和\(P(+)\)谁的概率大。该模型涉及两个问题,一个是树结构如何建立(word2vec中基于词频构建Huffman树,推荐领域可以根据不同类样本数构建),一个是树结构中非叶子节点的向量参数(可采用最大似然的思想求解该模型,其参数更新推导跟LR基本一致)。
Hierarchical Softmax的缺点是,当一个类别出现频率较低时,需要在霍夫曼树中向下走很久。Negative Sampling可以解决该问题。
构建二叉树
// Create binary Huffman tree using the word counts
// Frequent words will have short uniqe binary codes
void CreateBinaryTree() {
long long a, b, i, min1i, min2i, pos1, pos2, point[MAX_CODE_LENGTH];
char code[MAX_CODE_LENGTH];
long long *count = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));
long long *binary = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));
long long *parent_node = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));
for (a = 0; a < vocab_size; a++) count[a] = vocab[a].cn;
for (a = vocab_size; a < vocab_size * 2; a++) count[a] = 1e15;
pos1 = vocab_size - 1;
pos2 = vocab_size;
// Following algorithm constructs the Huffman tree by adding one node at a time
for (a = 0; a < vocab_size - 1; a++) {
// First, find two smallest nodes 'min1, min2'
if (pos1 >= 0) {
if (count[pos1] < count[pos2]) {
min1i = pos1;
pos1--;
} else {
min1i = pos2;
pos2++;
}
} else {
min1i = pos2;
pos2++;
}
if (pos1 >= 0) {
if (count[pos1] < count[pos2]) {
min2i = pos1;
pos1--;
} else {
min2i = pos2;
pos2++;
}
} else {
min2i = pos2;
pos2++;
}
count[vocab_size + a] = count[min1i] + count[min2i];
parent_node[min1i] = vocab_size + a;
parent_node[min2i] = vocab_size + a;
binary[min2i] = 1;
}
// Now assign binary code to each vocabulary word
for (a = 0; a < vocab_size; a++) {
b = a;
i = 0;
while (1) {
code[i] = binary[b];
point[i] = b;
i++;
b = parent_node[b];
if (b == vocab_size * 2 - 2) break;
}
vocab[a].codelen = i;
vocab[a].point[0] = vocab_size - 2;
for (b = 0; b < i; b++) {
vocab[a].code[i - b - 1] = code[b];
vocab[a].point[i - b] = point[b] - vocab_size;
}
}
free(count);
free(binary);
free(parent_node);
}
CBOW模型,求解Hierarchical Softmax源码
if (cbow) { //train the cbow architecture
// in -> hidden
cw = 0;
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) neu1[c] += syn0[c + last_word * layer1_size];
cw++;
}
if (cw) {
for (c = 0; c < layer1_size; c++) neu1[c] /= cw;
if (hs) for (d = 0; d < vocab[word].codelen; d++) {
f = 0;
l2 = vocab[word].point[d] * layer1_size;
// Propagate hidden -> output
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2];
if (f <= -MAX_EXP) continue;
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha;
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c];
}
// NEGATIVE SAMPLING
if (negative > 0) for (d = 0; d < negative + 1; d++) {
if (d == 0) {
target = word;
label = 1;
} else {
next_random = next_random * (unsigned long long)25214903917 + 11;
target = table[(next_random >> 16) % table_size];
if (target == 0) target = next_random % (vocab_size - 1) + 1;
if (target == word) continue;
label = 0;
}
l2 = target * layer1_size;
f = 0;
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1neg[c + l2];
if (f > MAX_EXP) g = (label - 1) * alpha;
else if (f < -MAX_EXP) g = (label - 0) * alpha;
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2];
for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * neu1[c];
}
// hidden -> in
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c];
}
}
}
Skip-Gram模型,求解Hierarchical Softmax源码
else { //train skip-gram
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
l1 = last_word * layer1_size;
for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
// HIERARCHICAL SOFTMAX
if (hs) for (d = 0; d < vocab[word].codelen; d++) {
f = 0;
l2 = vocab[word].point[d] * layer1_size;
// Propagate hidden -> output
for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1[c + l2];
if (f <= -MAX_EXP) continue;
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha;
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * syn0[c + l1];
}
// NEGATIVE SAMPLING
if (negative > 0) for (d = 0; d < negative + 1; d++) {
if (d == 0) {
target = word;
label = 1;
} else {
next_random = next_random * (unsigned long long)25214903917 + 11;
target = table[(next_random >> 16) % table_size];
if (target == 0) target = next_random % (vocab_size - 1) + 1;
if (target == word) continue;
label = 0;
}
l2 = target * layer1_size;
f = 0;
for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1neg[c + l2];
if (f > MAX_EXP) g = (label - 1) * alpha;
else if (f < -MAX_EXP) g = (label - 0) * alpha;
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2];
for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * syn0[c + l1];
}
// Learn weights input -> hidden
for (c = 0; c < layer1_size; c++) syn0[c + l1] += neu1e[c];
}
}
2.2 在candidate generation model的serving过程中,YouTube为什么不直接采用训练时的model进行预测,而是采用了一种最近邻搜索的方法?
这个问题涉及到两个点,一是user vector和item vector分别是什么?二是线上serving的时候,如何快速计算求得与用户最接近的item?
user vector与item vector分别从哪里来?
查看1.1中 YoutubeDNN 召回网络,可以看到:
-
对于user vector,底层特征经过三层网络计算即可得到。
-
对于item vector,training阶段进行softmax计算时,会为每一个类别(这里每一个类别对应一个物品)生成一组参数(详情阅读2.1问题),这组参数即为对应物品的vector。
serving 如何计算?
如果不做任何改进,serving 阶段需要计算一个用户vector与数百万物品vector的相似度,采用普通的方法很不容易计算。Youtube工程团队使用了一种LHS-MinHash近似算法来计算,也就是图中所说的’nearest neighbor index’。这种算法能够根据用户vector快速从海量物品vector中检索出最相似的物品。
2.3 Youtube的用户对新视频有偏好,那么在模型构建的过程中如何引入这个feature?
引入特征example age,其含义为日志上报时间到模型训练时间差,如某一数据上报时间为模型训练前24小时,则example age为24。引入该特征之后,可以使得模型学习到离训练这一时刻越近的样本,越符合用户当前兴趣,从而在模型中权重更大。线上预测时,将example age置为0则表达的是预测时刻用户最感兴趣的物品。
2.4 在对训练集的预处理过程中,YouTube没有采用原始的用户日志,而是对每个用户提取等数量的训练样本,这是为什么?
活跃用户的日志日志相对来说非常丰富,为了减少活跃用户对loss的影响,对每一位用户提取等量的训练样本
2.5 YouTube为什么不采取类似RNN的Sequence model,而是完全摒弃了用户观看历史的时序特征,把用户最近的浏览历史等同看待,这不会损失有效信息吗?
这个原因应该是YouTube工程师的“经验之谈”,如果过多考虑时序的影响,用户的推荐结果将过多受最近观看或搜索的一个视频的影响。YouTube给出一个例子,如果用户刚搜索过“tayer swift”,你就把用户主页的推荐结果大部分变成tayer swift有关的视频,这其实是非常差的体验。为了综合考虑之前多次搜索和观看的信息,YouTube丢掉了时序信息,讲用户近期的历史纪录等同看待。
2.6 在处理测试集的时候,YouTube为什么不采用经典的随机留一法(random holdout),而是一定要把用户最近的一次观看行为作为测试集?
Youtube该场景的目的是为了预测最新时刻用户的兴趣,所以使用最近一次的数据来当测试集再合适不过了。
2.7 在确定优化目标的时候,YouTube为什么不采用经典的CTR,或者播放率(Play Rate),而是采用了每次曝光预期播放时间(expected watch time per impression)作为优化目标?
这个问题从模型角度出发,是因为watch time更能反应用户的真实兴趣,从商业模型角度出发,因为watch time越长,YouTube获得的广告收益越多。而且增加用户的watch time也更符合一个视频网站的长期利益和用户粘性。这个问题看似很小,实则非常重要,objective的设定应该是一个算法模型的根本性问题,而且是算法模型部门跟其他部门接口性的工作,从这个角度说,YouTube的推荐模型符合其根本的商业模型,非常好的经验。方向错了是要让组员们很多努力打水漂的,一定要慎之又慎。
2.8 在进行video embedding的时候,为什么要直接把大量长尾的video直接用0向量代替?
这又是一次工程和算法的trade-off,把大量长尾的video截断掉,主要还是为了节省online serving中宝贵的内存资源。另外,从模型角度讲,低频video的embedding准确性较低。
2.9 针对某些特征,比如#previous impressions,为什么要进行开方和平方处理后,当作三个特征输入模型?
这是很简单有效的工程经验,引入了特征的非线性。从YouTube这篇文章的效果反馈来看,提升了其模型的离线准确度。
2.10 为什么ranking model不采用经典的logistic regression当作输出层,而是采用了weighted logistic regression?
因为在第7问中,已经知道模型采用了expected watch time per impression作为优化目标,所以如果简单使用LR就无法引入正样本的watch time信息,因此采用weighted LR,将watch time作为正样本的weight,在线上serving中使用e(Wx+b)做预测可以直接得到expected watch time的近似。
原创文章,转载请注明出处!
本文链接:https://leo4678.github.io/posts/dl-YoutubeDNN-question.html